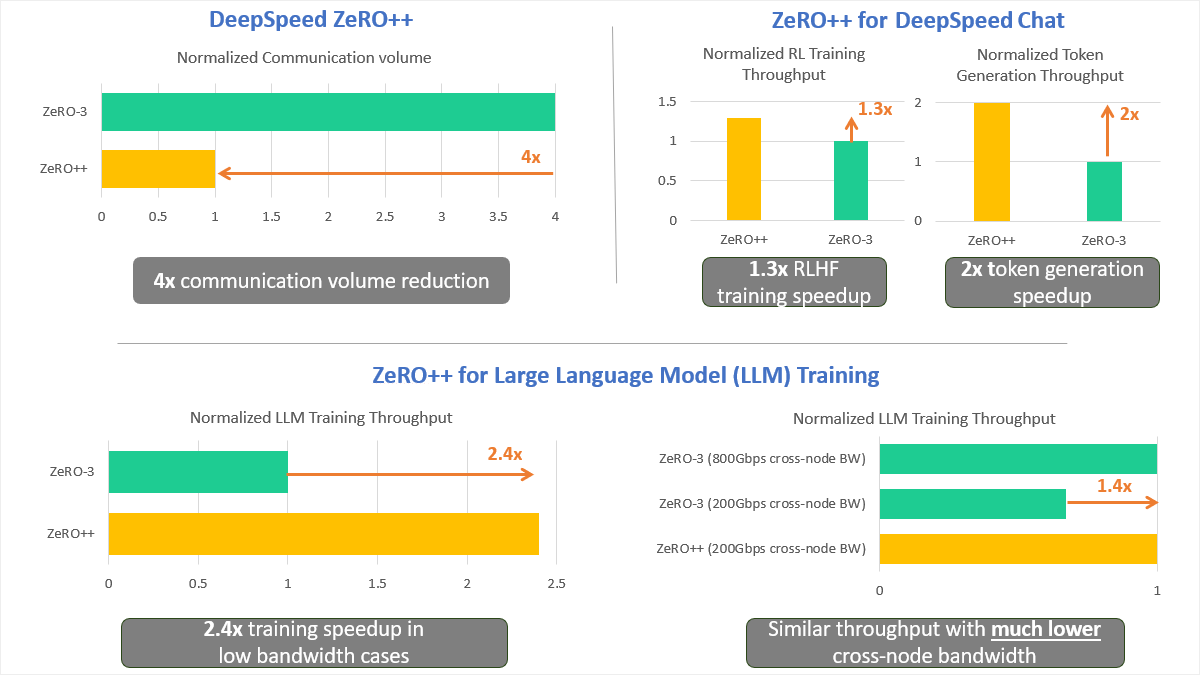
DeepSpeed ZeRO++ is a new optimization technique that reduces the communication and memory overhead of training large language models (LLMs) and chat models. It enables training LLMs and chat models with up to 170 billion parameters on a single GPU, and up to 13 trillion parameters on 512 GPUs, with 4x less communication than previous methods like ZeRO-3. It also improves the scalability, efficiency, and flexibility of LLM and chat model training, allowing researchers to explore new frontiers in natural language processing.